기본형 데이터 메모리 할당
기본형은 불변성 특징을 가진다. 한번 생성된 데이터는 변경될 수 없다.
기본형 - string, number, boolean, null, undefined, symbol, BigInt
변수에 값을 직접 저장하고 데이터 복사할 때는 값 자체가 복사된다.
cf. 참조형
메모리에 저장될 때 참조를 통해 접근하며, 데이터 타입은 크기가 가변적이고 불변적이지 않다.
참조형 - object, array, function, RegExp
메모리에 객체가 저장되고 변수는 그 메모리 주소를 참조한다. 복사를 할 때에는 메모리 주소 즉, 참조 값이 복사가 된다. 따라서 참조형 데이터가 복사된 변수들이 동일한 메모리 주소를 가리키게 함으로써 한 변수에서 객체를 수정하면 다른 변수에도 영향을 미친다.
기본형 데이터가 메모리에 배치되는 방식

let a = 1;
a라는 변수가 저장되는 변수 영역이 따로 있고, a에 대한 데이터가 저장되는 데이터 영역이 따로 있다.
<변수 영역> - 식별자를 위한 공간을 제공 변수명 a : 주소 @201 <데이터 영역> - 실제 값을 저장 주소 201 : 데이터 1

위와 같이 역할이 분리가 되어 있고 변수 영역에 값을 직접 할당하지 않고 데이터 영역에 값을 할당하는 이유는 메모리 효율과 값 복사의 단순화 때문이다. 아래와 같이 변수 a가 1을 할당하고 변수 b에 1을 할당할 때, 데이터 영역에 1이 이미 있는지 확인하고 있으면 기존의 1에 대한 주소값을 변수명 b에 할당한다. 값을 복사할 때도 마찬가지이다. 데이터 영역의 주소 값만 복사하면 되어 속도가 빠르다.
기본형 메모리 값 변경
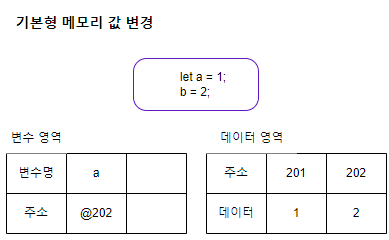
기본형 메모리 값 변경을 하는 방식은 다음과 같다.
위와 같은 예제에서는 숫자 2가 메모리 상에 있는지 확인한다. 없다면 변수 영역에서 원래 데이터 영역의 주소 (1에 대한)인 201이 아닌 새로운 데이터 주소인 202를 참조하고 데이터 영역에는 주소값 202로 2가 저장이 된다. 201 주소의 데이터 값을 2로 바꾸는 것이 아니다! 완전히 새로운 데이터 주소를 만들어서 2를 할당한다. 변수의 참조 값이 202로 업데이트 되어서 변수명 a는 새로운 주소 202를 가리키게 된다.
js 기본형 데이터는 불변성을 가진다. 불변성이란 한번 생성된 값은 변경될 수 없고, 값의 수정이 필요한 경우에는 새로운 값이 메모리에 할당 되어야 한다.
장점) 프로그램 안정성 및 예측 가능성
- 변수의 값이 변경되어도 다른 변수가 참조하는 값에는 영향을 미치지 않기 때문이다.
- 데이터의 상태 변경을 최소화 하여 부작용 방지, 프로그램 논리를 명확하게 만들 수 있다.
Q. 기존 변수에서 사용되던 숫자 1은?? 더 이상 참조되지 않는 상태가 되면 가비지 콜렉터에 의해 정리가 된다. 프로그램이 사용하지 않는 메모리를 자동으로 해지하는 것이다. 자바스크립트 엔진이 정기적으로 메모리를 스캔하여 도달할 수 없는 객체를 찾아 메모리를 해제한다.
+참고) 가비지 콜렉터의 동작 방식
마크앤 스윕 알고리즘으로 가비지 콜렉션 수행한다. 객체의 가능성을 판단하는 것이다. 루트 집합에서 시작하여 루트와 루트가 참조하는 객체, 그 객체가 참조하는 객체를 마킹한다. 이 과정에서 접근 가능한 모든 객체가 식별 된다. 마킹된 후에는 스윕 단계에서 메모리에서 마킹되지 않은 객체를 제거한다. (가비지) 즉, 프로그램에서 더이상 쓰이지 않는 데이터는 메모리 관리 시스템에 의해 자동으로 정리가 된다.
참조형 데이터 메모리 할당
참조형 데이터가 메모리에 배치되는 방식

참조형 데이터는 기본형 데이터와는 다르게 데이터 영역에서 바로 데이터 값이 할당되지 않는다. 참조형 데이터는 별도의 데이터 영역이 추가로 존재한다. 그 이유는 객체의 경우 여로 개의 변수와 값을 모아놓은 그룹이기 떄문에 데이터 영역 주소 201에 모든 데이터의 값을 저장할 수 없다. property 를 저장하는 메모리영역 401이 존재하고 property “name”은 문자열 “kim” 말고도 다른 값을 저장할 수도 있기 때문에 401에 메모리 주소에 바로 값을 할다하지 않고 데이터 주소인 202를 할당하고 202에 “kim”을 할당한다. 201 주소의 메모리 데이터가 @401~?의 의미는 객체의 property는 “name”에 더해 계속해서 확장될 수 있다는 의미이다.
정리하면, 참조형 데이터는 데이터 영역에 바로 값이 할당되지 않고 여러 개의 속성과 값을 포함할 수 있기 때문에 별도의 저장 영역이 추가로 존재한다.
⇒ 이유: 최초 데이터 할당 시에는 추가적인 메모리 할당으로 메모리가 늘어날 수 있지만, 결과적으로는 같은 값은 오직 하나만 저장할 수 있기 때문에 메모리를 효율적으로 사용할 수 있다. 값 복사 시에는 메모리 주소만 복사하면 되어 단순해지고 빨라진다.
참조형 데이터 값 변경
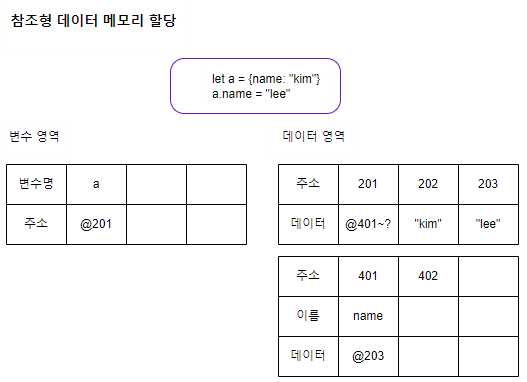
“name”의 값을 “kim”에서 “lee”로 변경
“lee”문자열이 메모리에 존재하는지 검색, 없으면 새로운 데이터 메모리 영역 203에 “lee”를 할당한다. 그리고 객체 a가 참조하는 메모리 주소는 201을 참조하고, 201메모리 주소는 401을 참조하고 있음. 이는 참조 체인이다. 참조 체인을 따라 원래 참조하고 있던 “name” property를 갖고 있는 메모리의 데이터 영역의 주소 202를 203으로 변경한다. 이 변경은 기존의 참조 관계를 새로운 데이터로 재지정하는 것을 의미한다. 이 과정으로 메모리 주소 간의 연결이 재구성 된다. 변경 후에 “kim”데이터를 참조하고 있던 기존의 메모리 주소 202는 이 주소를 참조하는 다른 변수나 객체가 없어서 이 데이터의 참조 카운트가 0이 되고 프로그램 내에서 사용되지 않기 때문에 가비지 컬렉터의 대상이 되어 제거가 된다.
기본형 데이터와 참조형 데이터의 값 변경의 차이

메모리 할당 방식의 차이 때문에 기본형 데이터는 불변성, 참조형 데이터는 가변성이 있다.
기본형 데이터는 1에서 2로 변경 시에 기존값 1이 저장된 메모리 주소 201에서 새로운 값이 저장된 메모리 주소 202로 변경이 된다. 새로운 값 2는 사용 가능한 빈 메모리 공간에 할당이 되고, 이전 값 과는 완전 별개의 메모리 주소를 갖게 된다. 따라서 기본형 데이터는 값이 변경 되더라도, 원본 데이터 자체가 변경 되는게 아니라, 새로운 데이터가 새로운 메모리 공간에 할당되어 불변성이 유지된다. 참조형 데이터를 살펴 보면, 객체 a의 “name” 속성 값을 변경하는 경우를 생각해보면, 객체 a는 “name” property 값이 변경이 되어도 참조하는 메모리 주소 201은 변경되지 않는다. a 객체의 "name" property가 "kim" 에서 "lee"로 변경 되어도 “name” property 프로퍼티가 참조하는 데이터 주소가 202에서 203으로 변경이 되었고 객체 a는 그대로 201을 참조한다. 이는 참조형 데이터가 실제 데이터 보다는 데이터가 가리키는 참조를 저장하기 때문이다. 따라서 객체 내부의 속성을 변경하더라도 참조하는 주소는 그대로 유지가 된다. 이러한 특성 때문에 참조형 데이터는 가변성을 가진다.
기본형 데이터는 그 값이 직접적으로 메모리에 저장이 되어서 불변성을 지니고, 참조형 데이터는 메모리 주소를 통해 데이터에 간접적으로 접근하기 때문에 가변성을 지닌다.
예제 코드
let a = 1;
let b = a;
b = 2;
console.log(a); // 1
console.log(b); // 2
console.log(a === b); // false
let c = { name: "chae" };
let d = c;
d.name = "chaechae";
console.log(c.name); // chaechae
console.log(d.name); // chaechae
console.log(c === d); // true
기본형
초기 단계에서 a와 b는 같은 값을 가지고 있다. 이후에 b에 새로운 값 2가 할당이 되면 메모리 상에서 새로운 주소 202에 2가 할당이 되고 b는 202를 참조하게 된다. 결과적으로 a와 b는 서로 다른 메모리 주소를 가지게 된다. 서로 다른 주소 값을 참조하고 있으므로 a===b는 false이다.
참조형
초기 단계에서 a와 b는 같은 값을 가지고 있다. property “name”이 "kim"에서 "lee"로 변경이 될 때 401에서 참조하던 202가 203으로 변경이 된다. 따라서 a와 b의 주소 값인 201에는 변동 사항이 없게 된다. 주소 값이 같기 때문에 a===b는 true이다. 문제가 될 수 있는 부분은 b객체의 "name" 값을 바꾸었는데, a객체의 "name" 또한 "kim"에서 "lee"로 변경이 된다.
참조형 데이터를 복사하고 수정할 때에는 주의가 필요하다!!!
얕은 복사와 깊은 복사
참조 주소값을 복사하는 것과는 다르다.
얕은 복사 - 객체의 최상위 레벨의 속성들만을 새로운 객체로 복사
Spread Operator, Object.assign(), Array.slice();
깊은 복사 - 객체의 모든 레벨에 대해 새로운 복사본 생성
⇒ 복사된 데이터는 원본 데이터와 독립적인 메모리 영역에 위치한다. 데이터의 안전한 관리와 부작용을 최소화한다.
JSON.parse(), 재귀함수, immer.js, lodash
얕은복사 Spread Operator 코드예시
let a = {
name: "chae", more: {
gender: "M"
}
};
let b = { ...a };
b.more.gender = "F";
b.name = "hyeong";
console.log(a); //{ name: 'chae', more: { gender: 'F' } }
console.log(b); //{ name: 'hyeong', more: { gender: 'F' } }
console.log(a === b); //false
a와 b객체는 서로 다르다고 하지만, 두 객체의 more.gender는 b에서만 바꾸었는데 a도 같이 바뀌어서 console에서 둘 다 F로 찍힌다. a와 b는 서로 다른 객체 이지만, 내부에 중첩된 객체는 동일한 참조를 서로 공유하고 있다고 볼 수 있다. JS에서 객체를 할당하거나 복사할 때 얕은 복사가 기본적으로 이루어지기 때문이다. 객체의 최상위 레벨은 새로운 복사본으로 생성이 되지만, 객체 내부의 중첩된 객체나 배열은 원본 객체의 참조를 공유하게 된다. 이러한 얕은 복사의 문제는 깊은 복사를 통해 해결가능하다. 깊은 복사는 객체의 모든 수준에 걸쳐 완전히 새로운 복사본을 생성한다. 이렇게 하면 원본 객체와 복사된 객체가 서로 영향을 주지 않는다.
// 깊은 복사
let a = {
name: "chae", more: {
gender: "M"
}
};
let c = JSON.parse(JSON.stringify(a));
c.more.gender = "F";
console.log(a); // { name: 'chae', more: { gender: 'F' } }
console.log(c); // { name: 'chae', more: { gender: 'M' } }
console.log(a === c); //false
a와 c는 완전히 서로 다른 메모리 주소를 참조한다.
JSON.parse(JSON.stringify(a))를 사용하는 깊은 복사의 원리는 이 객체를 json 문자열로 변환한다. 이 과정에서 객체의 모든 속성을 순회하면서 해당 속성은 문자열 형태로 변환하고, json 문자열을 js 객체로 다시 변환한다. 원본 객체의 구조적인 복사가 이루어진다. 원본 객체의 구조는 유지하고 새로운 메모리 주소에 할당된 새로운 객체가 생성된다. 이 방식은 약간의 문제가 있다. JSON.parse는 간하고 직관적이지만, 성능에 안 좋을 수 있다. JSON.parse는 전체 객체를 모두 복사를 하기 때문에, 복잡하거나 큰 객체에 대해서는 성능 상의 문제가 발생할 수 있다. 반면, immer.js와 같은 라이브러리는 필요한 부분만 복사를 하는 구조적 공유를 통해 성능을 향상 시킬 수 있다. 이 방식은 변경되지 않은 부분은 원본 객체의 참조를 유지한다. 변경된 부분만 새로운 객체로 만들어서 메모리 사용량과 처리 시간을 효율적으로 줄여준다. 또한, JSON은 순환 참조 등의 일부 데이터 타입이나 구조를 제대로 복사 하지 못한다는 단점이 있다. 반면, immer.js와 같은 라이브러리는 데이터 타입과 구조를 정확하게 다룰 수 있다. 따라서 간단한 객체 복사에는 JSON.parse를 사용하고 복잡한 상태 관리, 성능, 정교한 데이터 처리에는 라이브러리를 사용하는 게 좋다.
immer.js 코드
import {produce} from 'immer';
let a = {
more: {
gender: "male"
}
};
let b = produce(a, draft => {
draft.more.gender = 'female';
});
console.log(a === b);
console.log(a.more.gender);
console.log(b.more.gender);
Q. 리액트에서 불변성을 유지해야 한다는 의미
상태를 변경할 때 원본 객체나 배열을 직접 수정하지 않고 새로운 복사 본을 만들어 사용해야 한다. 객체나 배열 같은 참조형 데이터 일 때만 참조를 통한 복사가 아닌, 얕은 복사와 깊은 복사를 통해 참조 값 복사가 아닌 값 복사가 필요하다. 배열이나 객체 같은 참조형 데이터는 얕은 복사나 깊은 복사를 통해 상태 변경 시 원본을 직접 수정하지 않고 새로운 복사본을 생성하여 사용해야 한다.
리액트는 함수형 프로그래밍의 개념을 채택하고 있다. 불변성은 함수형 프로그래밍에서 중요한 역할을 한다. 이는 데이터를 변경하지 않고 새로운 데이터를 생성하여 부작용을 방지하고 프로그램의 예측 가능성을 높인다. 불변성을 통해 프로그램의 상태가 시간이나 외부 요인에 의해 예기치 않게 바뀌는 것을 방지할 수 있고, 함수 간의 데이터 흐름이 명확하여 디버깅과 테스팅이 수월하다. 병렬 처리와 같은 멀티 스레딩 환경에서 데이터 충돌을 줄이는 데에도 중요하다.
리액트는 이전 상태와 새 상태를 비교하여 필요한 부분만 리렌더링한다. 참조형 데이터의 불변성 때문에, 객체나 배열 내부의 데이터가 변경이 되어도 참조가 동일하여 새 상태로 인식하지 못하고 리렌더링 하지 않을 수도 있다. 불변성을 유지하여 리액트가 상태변화를 정확히 감지하고 ui를 올바르게 업데이트하게 하는 것이 매우 중요하다. 불변성은 성능 최적화와 안정적인 상태 관리에 도움이 된다. 불변성은 ui를 효과적으로 업데이트 할 수 있고 어플리케이션의 상태 변화를 쉽게 추적할 수 있다. 불변성은 컴포넌트의 순수성을 유지하고 복잡한 상태 관리에서 발생하는 버그를 줄여줄 수 있다.
[참고]
패스트캠퍼스 강의 (내 생에 마지막 JavaScript : 기초 문법부터 실무 웹 개발까지 한 번에 끝내기 초격차 패키지 Online) 를 기반으로 작성하였고, 추가 서치 내용을 정리하였습니다.
'개발공부 > Javascript' 카테고리의 다른 글
| [JS] 이벤트 버블링과 캡처링 (0) | 2024.04.04 |
|---|---|
| [JS] 호이스팅 (0) | 2024.03.28 |
| [JS] JavaScript 프로젝트에서 스타일 설정 방법 3가지 코드 예시 (1) | 2024.03.18 |
| [JS] 실행 컨텍스트 (1) | 2024.03.13 |
| [JS] 클로저 (0) | 2024.03.11 |